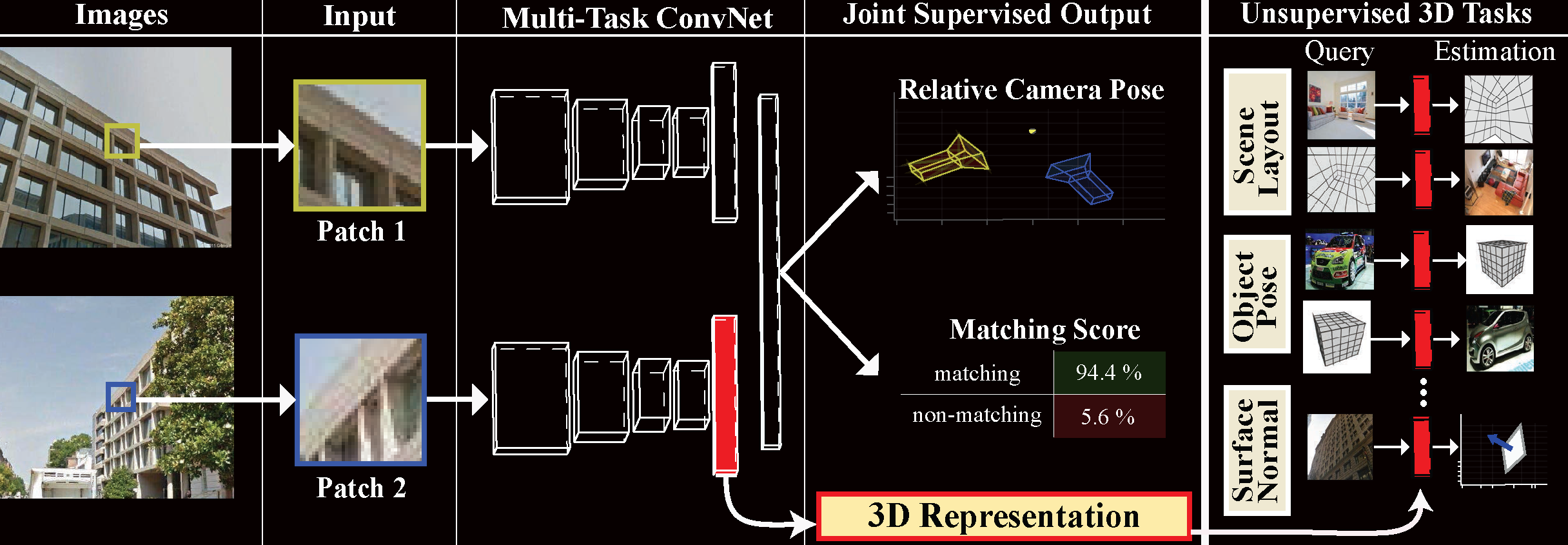
Generic 3D Representation via Pose Estimation and Matching
What does it take to develop an agent with human-like intelligent visual perception? The popular paradigms currently employed in computer vision are problem-specific supervised learning, and to a lesser extent, unsupervised and reinforcement learning. However, we argue that none of these would lead to truly intelligent visual perception unless the learning framework is specifically devised to gain abstraction and generalization power. Here we show our approach to this problem which is inspired by the developmental stages of vision skills in humans. Specifically, rather than training a new model for every individual desired problem, we train a model to learn fundamental vision tasks that serve as the foundation for ultimately solving the desired problems. As our first effort towards validating this approach, we employ this method to learn a generic 3D representation through supervising two basic but fundamental 3D tasks. We show that the learned representation generalizes to unseen 3D tasks without the need to any fine-tuning while it achieves a human-level performance on the task it was supervised for.
Representation Learning Pipeline
Our method is based upon the premise that by providing supervision over a set of carefully selected foundational tasks, generalization to unseen tasks and abstraction capabilities can be achieved. We use this approach to learn a generic 3D representation through solving a set of supervised proxy 3D tasks: object-centric camera pose estimation and wide baseline feature matching (please see the paper for a discussion on how these two tasks were selected). We empirically show that the internal representation of a multi-task ConvNet trained to solve the above problems generalizes to unseen 3D tasks (e.g., scene layout estimation, object pose estimation, surface normal estimation) without the need to fine tuning and shows traits of abstraction abilities (e.g., cross modality pose estimation).
In the context of the supervised tasks, we show our representation achieves state-of-the-art wide-baseline feature matching results without requiring apriori rectification (unlike SIFT and the majority of learned features). We also demonstrate 6DOF camera pose estimation given a pair local image patches.
How we collected the Data
We contribute a large-scale dataset composed of object-centric Street View scenes along with point correspondences and camera pose information. We collected the dataset by integrating Street View images, their metadata, and large-scale geo-registered 3D building models scraped on the web. The simplified steps of collecting the dataset is show in the above animation (see the paper for details). The dataset is available to public for research purposes and currently includes the main areas of Washington DC, New York City, San Francisco, Paris, Amsterdam, Las Vegas, and Chicago. To ensure the quality of the test set and keep evaluations unimpacted by potential errors introduced by the automated data collection, every datapoint in the test set are verified by at least three Amazon Mechanical Turkers. The procedure and statistics are elborated in the supplementary material.
DOWNLOAD VISUALIZATIONS AND ACCURACY ANALYSIS OF THE TEST SET [HERE]
Sample Collected Image Bundles
select a page
←GIF | Images→
←GIF | Images→
←GIF | Images→
←GIF | Images→
Each row depicts a sample collected image bundle. Each bundle shows one target physical point
(placed in the center of the images) from different viewpoints.
Below you can see a few snapshots of 3D models of the 8 cities using which the dataset was collected. You can see more snapshots here. The 3D models are also available for download.
Results: the learned representation
We investigate the properties of the learned representation using the following methods:
1) tSNE: large-scale 2D embedding of the representation. This enables visualizing the space and getting a sense of similarity from the perspective of the representation,
2) Nearest Neighbors (NN) on the full dimensional representation
3) training a readout function (a simple classifier, such as KNN or a linear classifier) on the frozen representation (i.e., no tuning) to read out a desired variable.
We refrain from fine tuning the representation (i.e., the siamese tower is frozen and receives no supervision on the task it is being evaluated on). This is because, if our initial hypothesis is correct, training on the foundational tasks should essentially lead to generalization and abstraction with no direct supervision on the secondary tasks.
We compare against the representations of related methods that made their models available, various layers of AlexNet trained on ImageNet, and a number of supervised techniques for some of the tasks.
tSNE (MIT Places & OUR DATASET)
The 2-dimensional embeddings (tSNE) of our representation for MIT places dataset (‘library’ category) and an unseen subset of our dataset are provided below. The representation organizes the images based on their 3D content (scene layout, relative camera pose to the scene, etc) and independent of their semantics (visible objects, architectural styles) or low-level properties (color, texture, etc). This suggests that the representation must have a notion of certain basic 3D concepts, though it was never provided with an explicit supervision for such tasks (especially for non-matching images, while all tSNE images are non-matching).
The tSNE of our dataset also suggests the patches are organized based on their coarse surface normals (again, a task that the representation didn’t receive a supervision for). See the section below for quantitative evaluation of our representation for surface normal estimation on NYUv2 dataset.
select a page hover over the figure for magnification
Click on a query image to see its NNs based AlexNet (trained on ImageNet) and our representation.
Note the geometric consistency between the NNs and their respective query.
click on a query image
Query Image:
Pose:
Alexnet:
Surface Normal Estimation
We evaluated our representation on NYUv2 benchmark to see if it has a notion of surface normals (see the discussion on the tSNEs above).
The summary of the results are provided below, showing our representation outperforms the baselines on unsupervised surfance normal estimation (see the paper for more details and additional results).
3D OBJECT POSE ESTIMATION
The following figures shows the tSNE embedding of several ImageNet categories based on our representation and AlexNet trained on ImageNet. Please see the paper for the tSNEs of other baseline representations. The embeddings of our representation are geometrically meaningful, while the baselines either perform a semantic organization or overfit to other aspects, such as color.
NOTE: certain aspects of object pose estimation, e.g. distinguishing between the front and back of a bus, are more of a semantic task rather than geometric/3D. That adversely impacts a method that has a 3D understanding but not semantic (e.g., our representation). In this sense, the poses that are 90 degrees congruent could be considered identical and equally good (i.e., different sides of an even cube).
IMAGENET
select a page hover over the figure for magnification
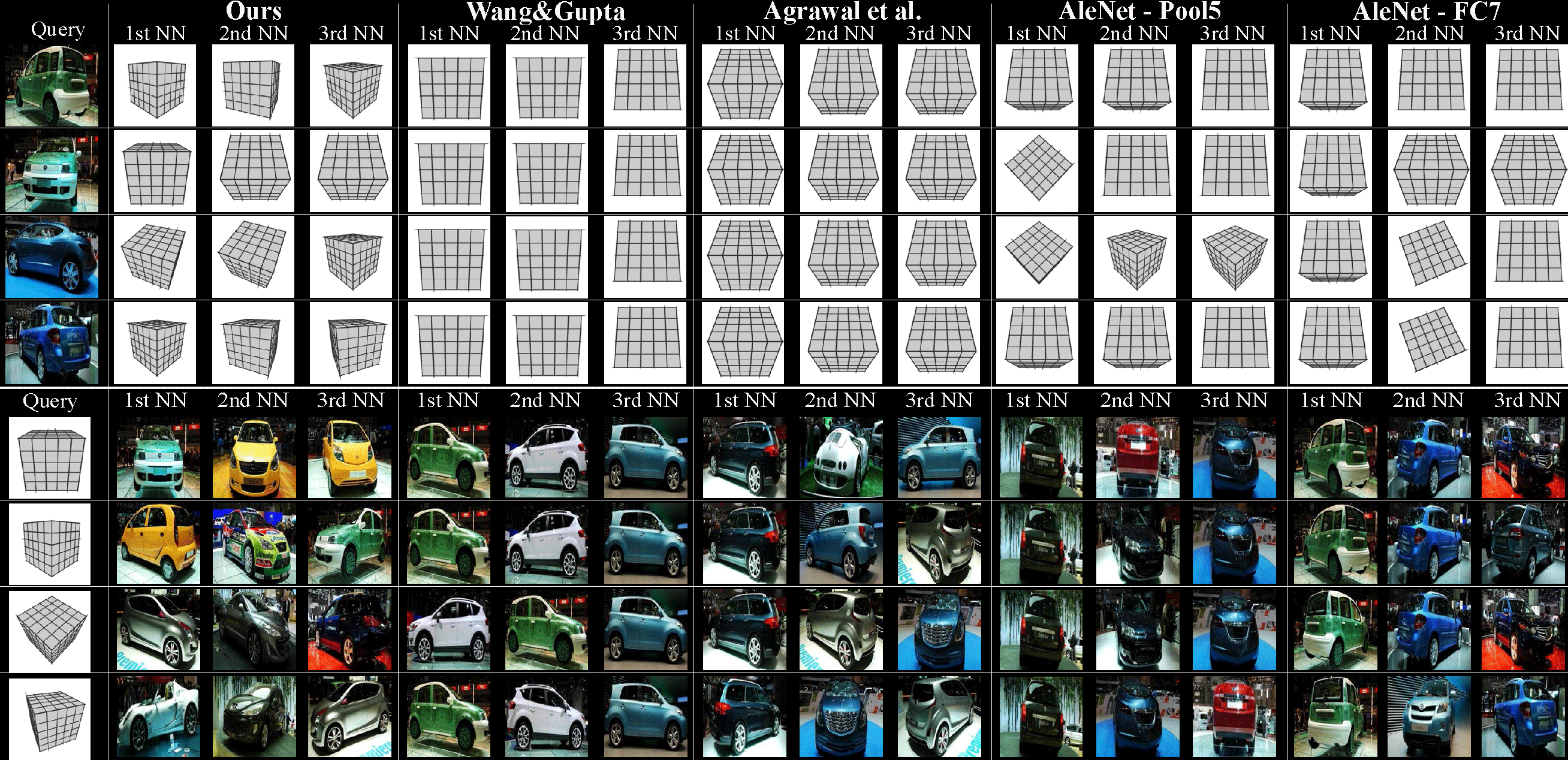
To evaluate the abstract generalization abilities of our representation, we generated a sparse set of 88 images showing the exterior of a synthetic cube parametrized over different view angles. The images can be seen as an abstract pose of an object. We then performed NN search between these images and the images of EPFL Multi-View Car dataset using our representations and several baselines. As apparent in the following figure, our representation retrieves meaningful NNs while the baselines mostly overfit to appearance and retrieve either an incorrect or always the same NN. This suggests that our representation, unlike the baselines, has been able to abstract away the appearance details irrelevant for a basic 3D understandin.
PASCAL 3D
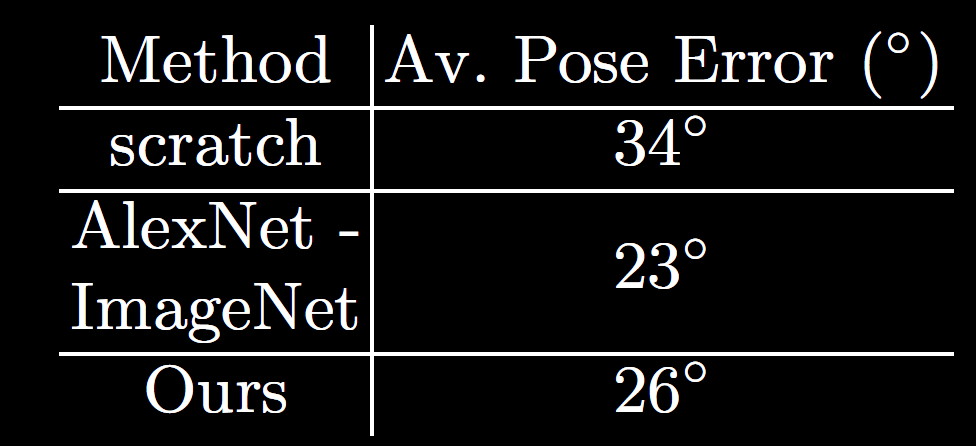
The following figure shows cross-category NN search results for our representation along with several baselines. This also evaluates a certain level of abstraction as some of the object categories can be drastically different looking. We also quantitatively evaluated on 3D object pose estimation on PASCAL3D with the results available in the following table. Our representation outperforms scratch network and comes close to AlexNet that has seen thousands of images from the same categories from ImageNet and other objects.
Quantitative results on PASCAL3D benchmark
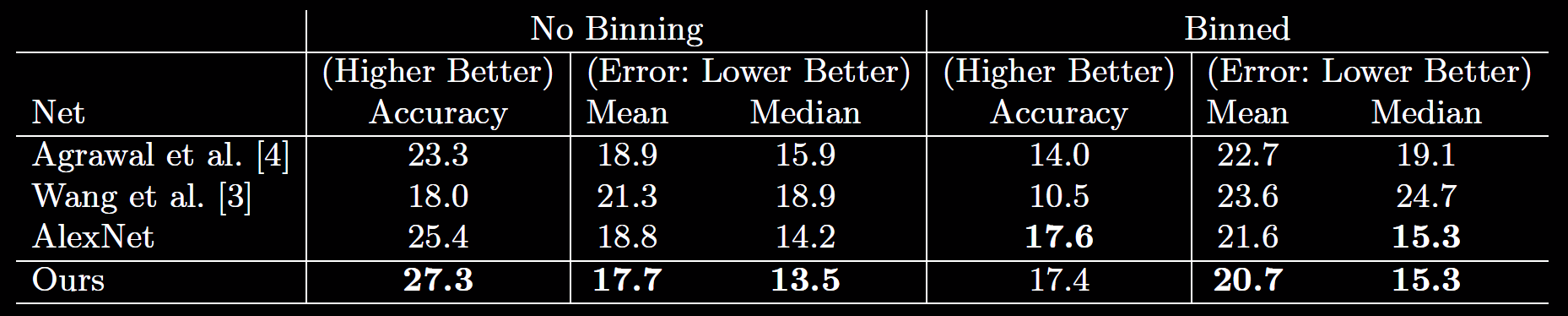
Scene layout estimation
We evaluated our representation on LSUN dataset. The right table provides the results of layout estimation using a simple NN classifier on our representation along with two supervised baselines, showing that our representation achieved a performance close to Hedau et al.'s supervised method on this unseen task. The left table provides the results of 'layout classification' using NN classifier on our representation and to AlexNets FC7 and Pool5 representations.
Quantitative results on LSUN benchmark
ABSTRACTION OF Layout Estimation
We performed an abstraction experiment on layout estimation (similar to the one on 3D object pose shown above). We performed NN retrieval between a set of 88 images showing the interior of a synthetic cube and the images of LSUN dataset. The same observation of the abstraction experiment on 3D object pose is made here as well with our NNs being meaningful while the baselines mostly overt to appearance with no clear geometric abstraction trait.
Results: Supervised Tasks
The qualitative and quantitative results of evaluations on the supervised tasks can be seen below. We used the standard evaluation protocols for both camera pose estimation and feature matching tasks. We also provide evaluation results on the (non-Street View) benchmarks of Brown et al. and Mikolajczyk&Schmid.
Qualitative Results of Camera Pose Estimation
Qualitative Results of Matching
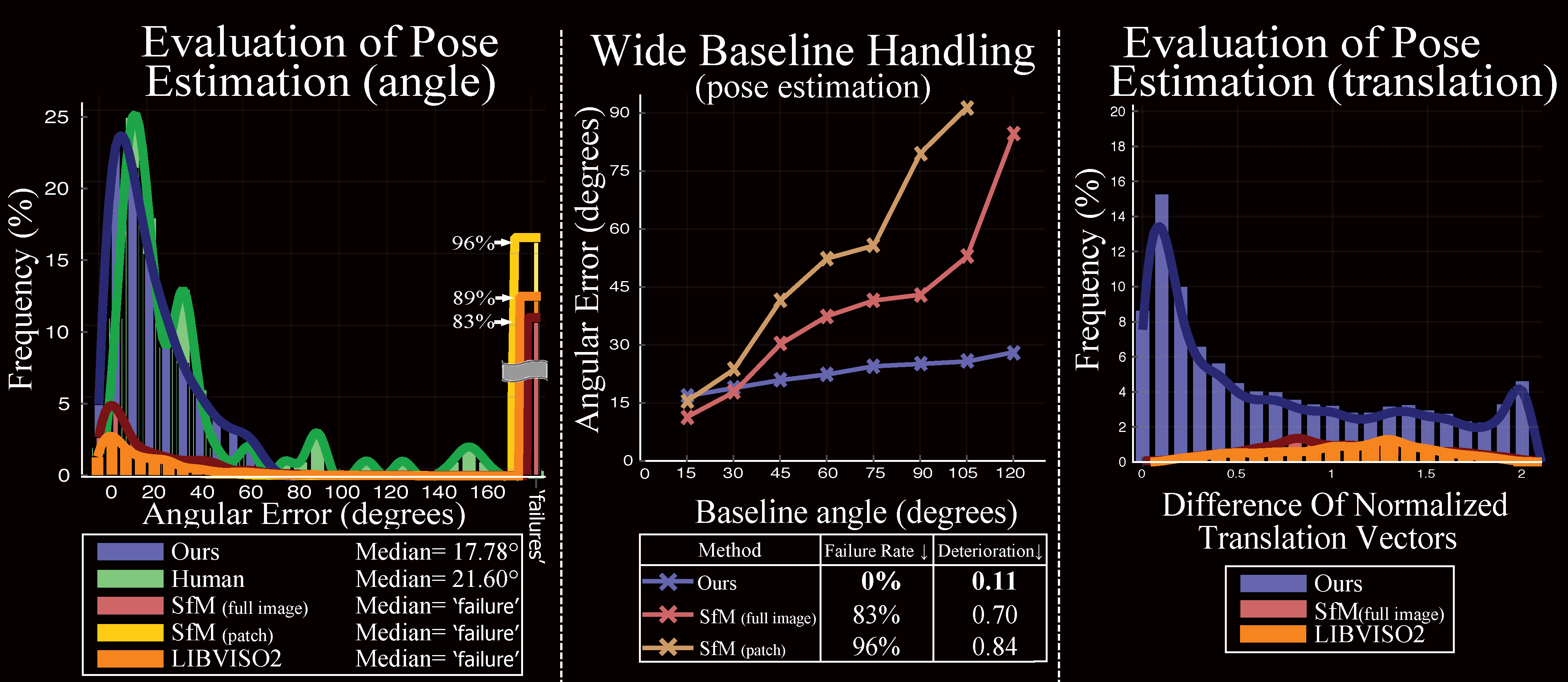
Quantitative Evaluation of Camera Pose Estimation
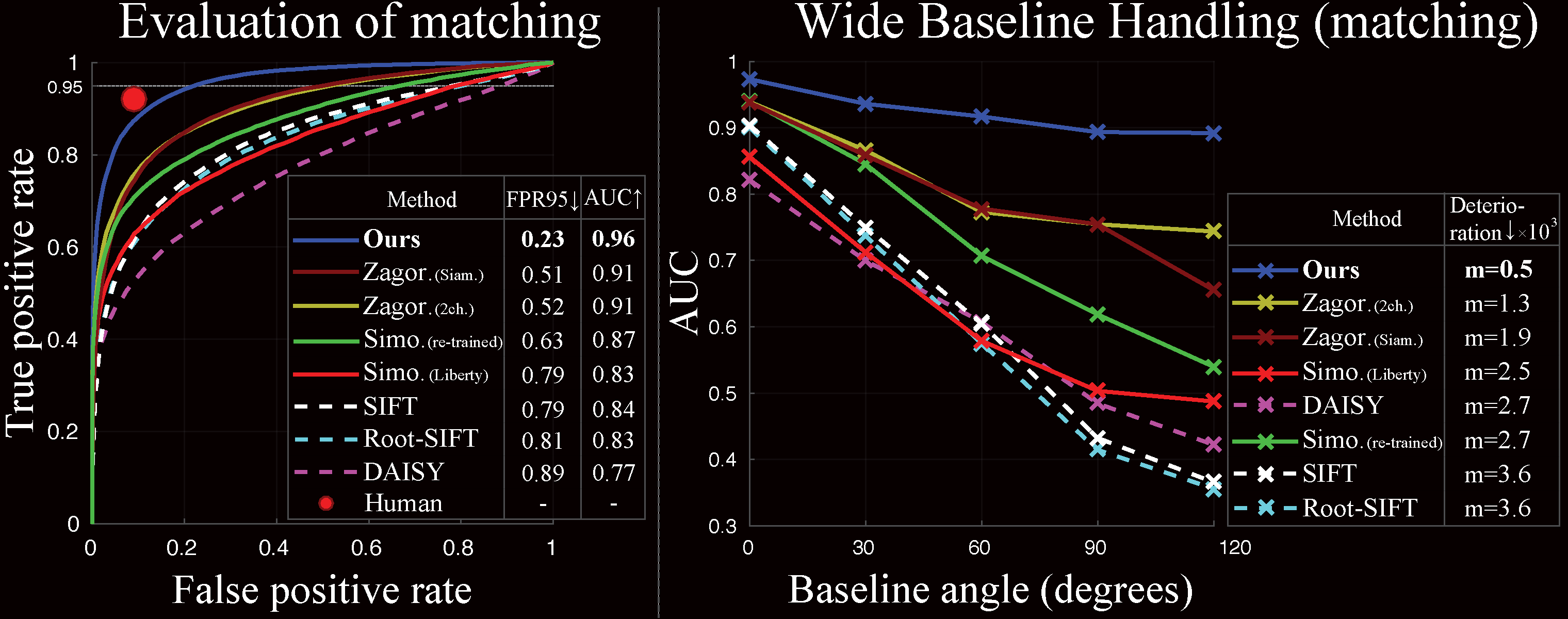
Quantitative Evaluation of Feature Matching
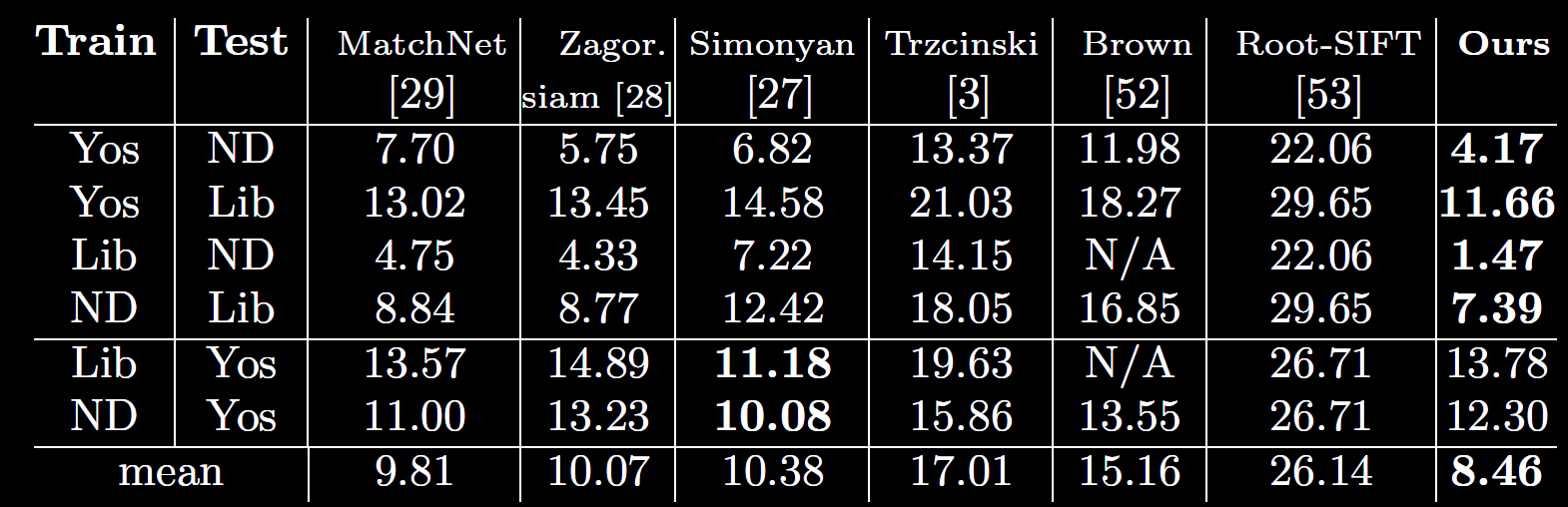
Evaluations on Brown's feature learning Benchmark (the metric is FPR@95)
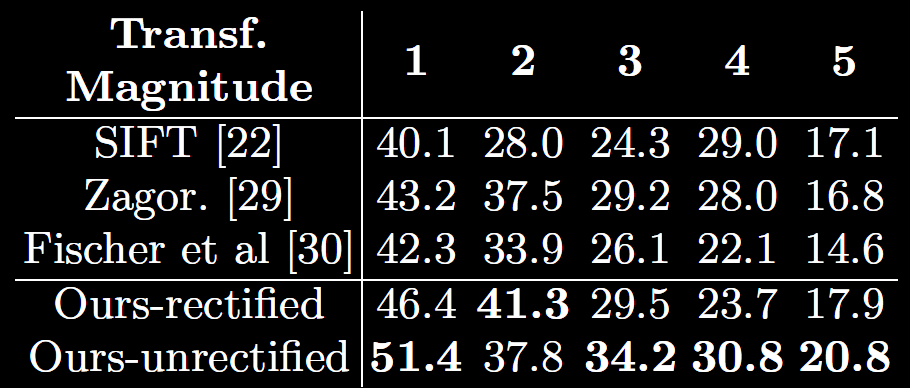
Evaluation on Mikolajczyk & Schmid's feature matching benchmark
Live Demo
Follow the instructions to upload a pair of images. Press Run and the relative camera pose and matching score between the two will be shown.
You can also upload a batch of (<100) images and receive the 2D embedding of our representaion vs the baselines reported in the paper.
What's Next?
We developed a generic 3D representation through solving a set of supervised core proxy tasks. We reported state-of-the-art results on the supervised tasks and showed the learned representation manifests generalization and abstraction traits. However, a number of questions remain open:
Though we were inspired by cognitive studies in defining the core supervised tasks leading to a generalizable representation, this remains at an inspiration level. Given that a `taxonomy' among basic 3D tasks has not been developed, it is not concretely defined which tasks are fundamental and which ones are secondary. Developing such a taxonomy (i.e., whether task A is inclusive of, overlapping with, or disjoint from task B) would be a rewarding step towards soundly developing the ‘3D complete’ representation. Also, semantic and 3D aspects of the visual world are tangled together. So far, we have developed independent semantic and 3D representations; investigating concrete techniques for integrating them (beyond simplistic late fusion or ConvNet fine-tuning) is a worthwhile future direction for research. Perhaps, inspirations from partitions of visual cortex could be insightful towards developing the ultimate ‘vision complete’ representation.